
Observability to AIOps: Transforming Anomaly Detection for Modern Enterprises
by Raja Shekar Mulpuri | Dec 19, 2024

As businesses increasingly digitize operations, IT systems are evolving into complex, distributed ecosystems. Applications run across multi-cloud environments, microservices power critical processes, and data flows in real time across countless touchpoints. While this transformation drives agility and scalability, it introduces significant challenges: hidden anomalies that can disrupt operations, frustrate users, and damage revenue.
The traditional approach of monitoring—where IT teams set fixed thresholds and wait for alerts—is no longer sufficient. Static alerts struggle to identify anomalies that don’t align with pre-defined rules. By the time issues are flagged, the damage is often done. This is why enterprises today are embracing observability and AIOps. Together, they enable real-time anomaly detection while automating the identification of patterns, predicting issues, and accelerating root cause analysis.
This shift isn’t just a technological evolution—it’s a strategic necessity for businesses operating in an increasingly dynamic and competitive environment.
The Current Challenges Enterprises Face
Modern IT infrastructures are more distributed and complex than ever before, with systems spanning multiple layers: cloud services, virtualized servers, containers, APIs, and third-party integrations. With such distributed systems come significant challenges:
Siloed Monitoring Tools: Enterprises often use fragmented tools for specific layers—servers, applications, or networks—leading to blind spots. IT teams lack a single pane of glass view across the ecosystem.
Data Overload: Today’s systems generate massive amounts of telemetry data—logs, metrics, traces—that traditional tools cannot handle effectively. IT teams are overwhelmed by the sheer volume of noise and irrelevant alerts.
Dynamic Systems, Static Thresholds: Modern systems are dynamic and elastic, making it impossible for static rules or thresholds to define what’s “normal.” This results in frequent false positives or undetected anomalies.
Manual Root Cause Analysis: When anomalies occur, IT teams spend countless hours manually piecing together data, leading to prolonged Mean Time to Identify (MTTI) that results in prolonged Mean Time to Resolution (MTTR).
Proactive vs Reactive Operations: Teams respond to problems after disruptions rather than preventing issues altogether.

These challenges have made anomaly detection—the ability to identify and act on unusual system behavior—one of the most critical capabilities for enterprise IT.
The Need for Observability
Businesses are accelerating their investment in observability and AI-driven operations. According to Gartner, by 2026, 70% of organizations will have implemented observability to optimize performance and reduce downtime. The observability market itself is growing rapidly, projected to reach $5.7 billion by 2028, with a CAGR exceeding 14%.
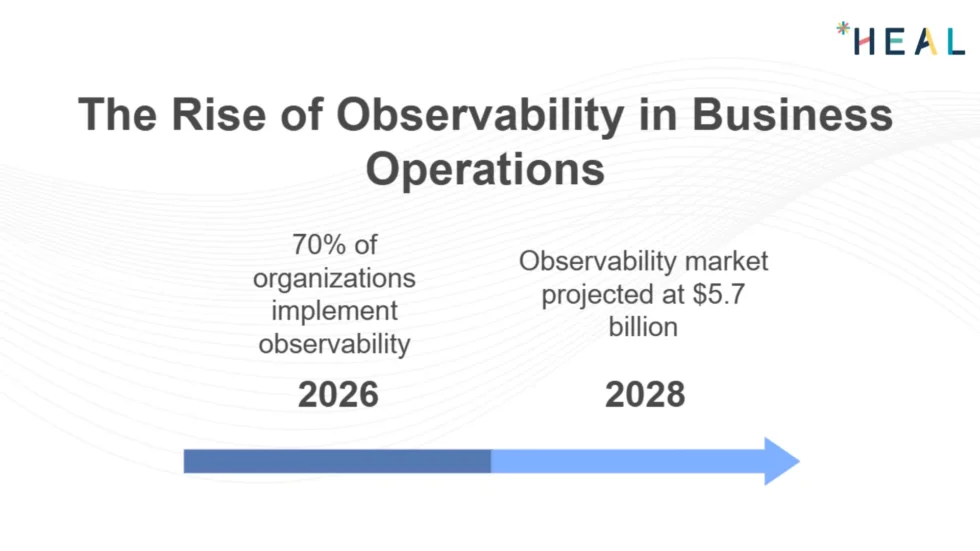
Several factors have fueled this shift:
The Growth of Cloud-Native Architectures: With businesses adopting microservices and Kubernetes, the complexity of managing interconnected components has skyrocketed.
High Downtime Costs: A 2023 IDC report estimates that every hour of downtime costs large enterprises an average of $500,000 in lost revenue and productivity.
The Demand for Resiliency: Enterprises are under pressure to deliver flawless user experiences in real time. Observability ensures system health is proactively managed.
Enterprises are no longer asking whether they need observability—they’re asking how quickly they can implement it across their IT infrastructure.
What Made Enterprises Turn to Observability?
Observability addresses the gaps left by traditional monitoring tools. While monitoring informs “What’s wrong?”, observability informs “Why is it wrong?” and “How can we fix it?”
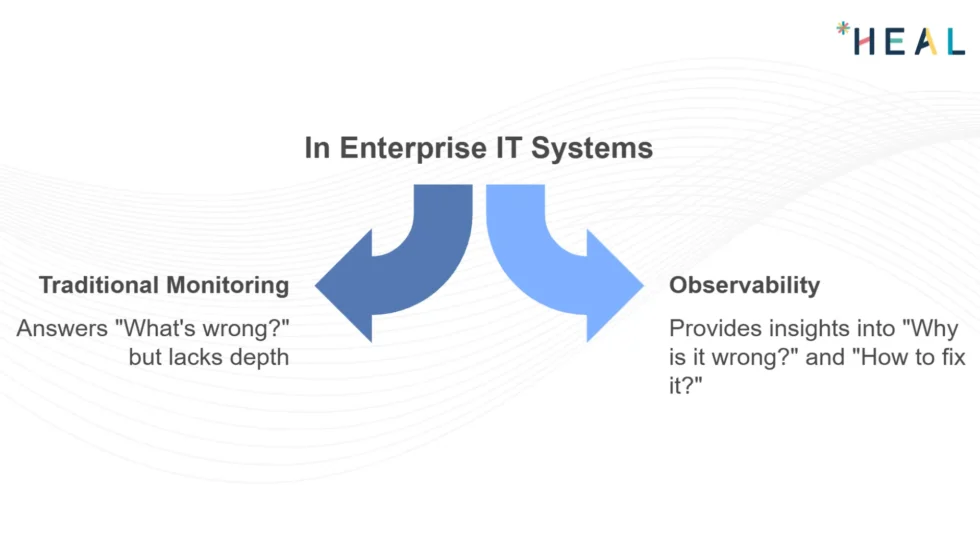
The primary drivers pushing enterprises toward observability include:
Dynamic, Distributed Systems: Microservices and containerized applications introduce complexity that legacy monitoring tools cannot manage. Observability offers end-to-end visibility across distributed environments.
Real-Time Requirements: Businesses can no longer afford to wait for alerts when customers demand zero downtime and seamless digital experiences. Observability enables real-time detection and resolution of anomalies.
Root Cause Analysis: Observability combines logs, metrics, and traces to provide context. For example, a spike in error rates can be traced to a failing microservice downstream, saving teams hours of investigation.
However, observability alone isn’t enough in environments where the volume of telemetry data is overwhelming. This is where AIOps complements observability, scaling anomaly detection and taking IT operations to the next level.
How AIOps Complements Observability for Anomaly Detection
While observability lays the foundation by collecting, correlating, and analyzing telemetry data, AIOps enhances it with intelligence, automation, and predictive insights. AIOps uses advanced algorithms and machine learning to extract actionable insights from the data observability platforms generate.

Here’s how they work together:
Identifying Unusual Patterns: Observability tools analyze logs, metrics, and traces to uncover patterns that deviate from normal behavior. For example, a surge in CPU usage may be flagged as unusual based on historical data.
Outlier Detection with AIOps: AIOps builds on observability by detecting anomalous events in operational data. Using AI, it identifies outliers that would otherwise go unnoticed, such as sudden transaction drops that correlate with latency spikes.
Pattern Recognition and Correlation: While observability captures data across multiple layers, AIOps correlates events to identify the root cause. If a spike in user errors occurs simultaneously with database timeouts, AIOps connects the dots to surface actionable insights.
Noise Reduction: IT teams are often overwhelmed by redundant alerts. AIOps reduces alert fatigue by analyzing patterns, filtering false positives, and prioritizing critical anomalies that require immediate attention.
Predictive Anomaly Detection: By analyzing historical data and trends, AIOps predicts anomalies before they occur. For instance, it might warn of a memory leak in a microservice hours before it causes a crash.
Automated Remediation: Beyond detection, AIOps enables automated workflows to resolve anomalies. A failing node can be restarted, resources can be scaled automatically, or microservices can be rolled back to a stable state—without human intervention.
The synergy between observability and AIOps transforms anomaly detection into a proactive, automated process. Enterprises gain the ability to predict, identify, and resolve issues before they impact users.
Proactive and Self-Healing Systems
As observability and AIOps continue to evolve, the future of anomaly detection is clear: systems that are proactive, intelligent, and self-healing. Artificial intelligence will move beyond identifying anomalies to understanding their business impact, correlating technical issues with real-world outcomes like lost revenue or user churn.
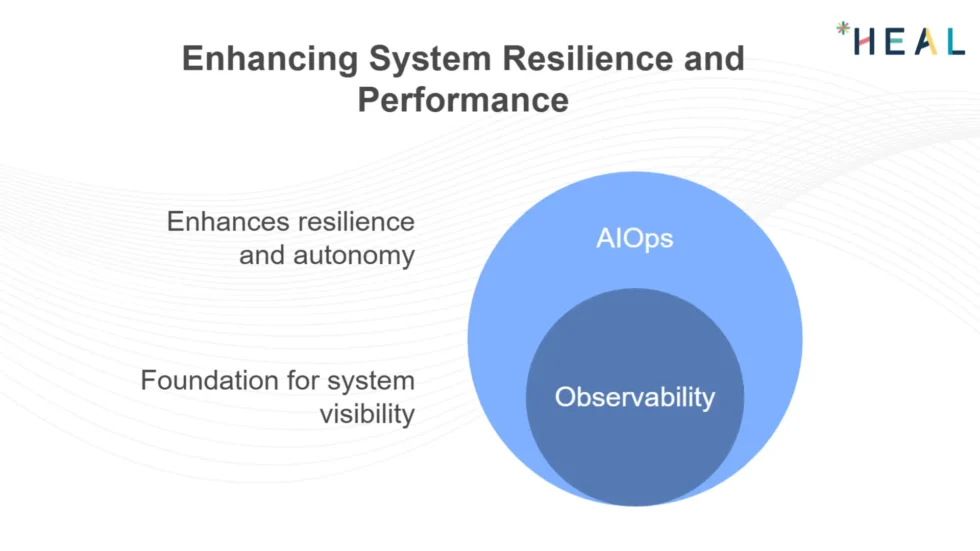
For IT teams, this means less time firefighting and more time innovating. Anomalies will no longer be disruptive surprises but predictable events that are detected, understood, and resolved automatically.
Observability will remain the foundation for visibility, while AIOps will ensure systems are resilient, autonomous, and optimized for performance.
Building the Future of IT Operations
Enterprises today face immense pressure to ensure their systems are reliable, scalable, and always available. Observability and AIOps are no longer optional tools—they are strategic imperatives for businesses seeking to survive and thrive in a digital-first world.
Observability provides the clarity and insight organizations need to detect anomalies in real time. AIOps complements this with the intelligence and automation to resolve issues proactively and predict failures before they happen. Together, they represent the next evolution in IT operations: systems that are not only monitored but understood and managed intelligently.
This is where HEAL, as a leading AIOPS player, complements observability with AI-driven precision. Together, these technologies ensure seamless, uninterrupted digital experiences.
With HEAL leading the way, enterprises gain a strategic edge, turning IT operations into a competitive advantage. The future of anomaly detection is here—and HEAL is at the forefront of this transformation.
About HEAL Software
HEAL Software is a renowned provider of AIOps (Artificial Intelligence for IT Operations) solutions. HEAL Software’s unwavering dedication to leveraging AI and automation empowers IT teams to address IT challenges, enhance incident management, reduce downtime, and ensure seamless IT operations. Through the analysis of extensive data, our solutions provide real-time insights, predictive analytics, and automated remediation, thereby enabling proactive monitoring and solution recommendation. Other features include anomaly detection, capacity forecasting, root cause analysis, and event correlation. With the state-of-the-art AIOps solutions, HEAL Software consistently drives digital transformation and delivers significant value to businesses across diverse industries.