
AIOps for Hybrid and Multi-Cloud: Operating at Enterprise Scale
by Renuka Suresh | Apr 8, 2026
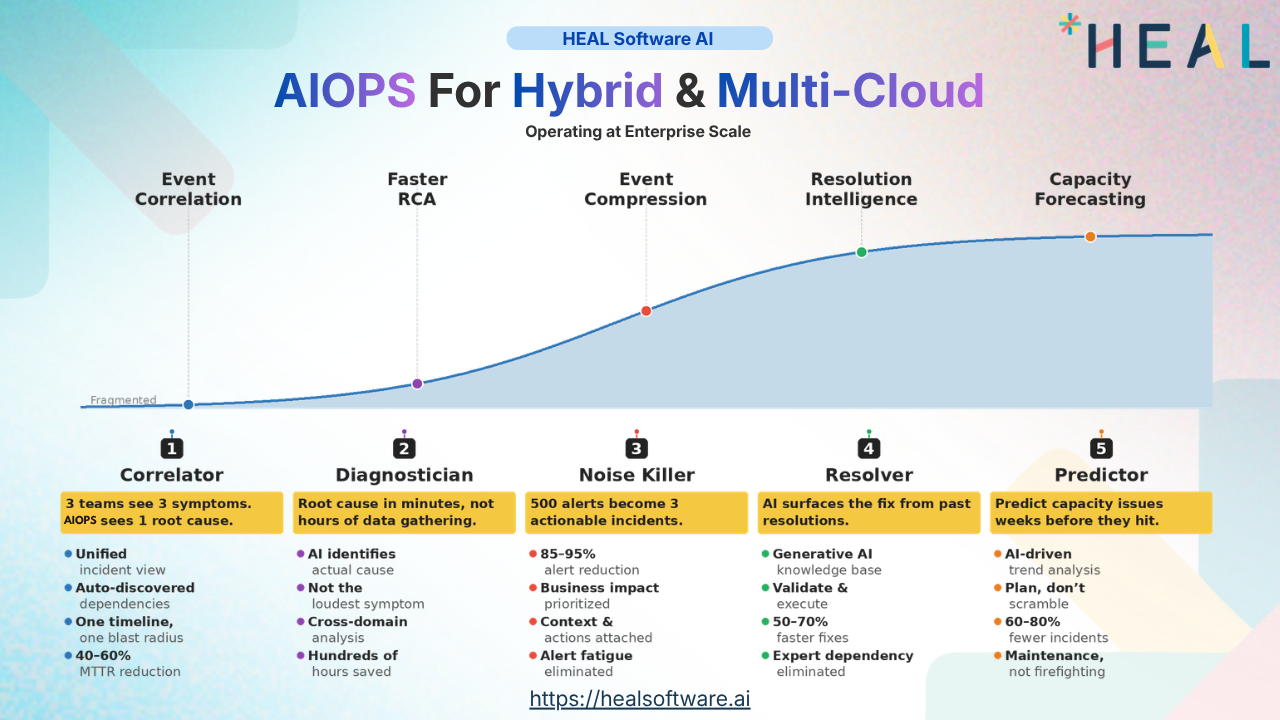
Here is a reality check for every CTO, IT Director, and Application Head reading this: your multi-cloud strategy is already more complex than your team thinks it is.
Your AWS team has CloudWatch. Your Azure team has Azure Monitor. Your on-prem team has Nagios or Zabbix. Your application team has New Relic or Datadog. Your security team has Splunk. And none of these tools share a common event model, a unified topology view, or a single correlation engine that can trace an incident from a customer's browser through a CDN, into an Azure front-end, across an API gateway running on AWS, down to a database sitting in your private data center.
Each cloud provider gives you excellent visibility within its own walls. But the incidents that bring enterprises down at scale are the ones that cross those walls, cascading failures that start in one environment and ripple through three others before anyone understands the causal chain.
You Have Visibility Everywhere and Insight Nowhere
Most discussions about "multi-cloud operations" treat it as a technology problem. Actually, it is an intelligence problem.
Technology-wise, most enterprises are well-instrumented. They have monitoring in AWS. They have monitoring in Azure. They have monitoring on-prem. They are collecting metrics, logs, and events from virtually every component in their infrastructure. The tooling exists. The data exists.
What does not exist is a single pane of intelligence that can reason across all of it simultaneously.
And this is not a minor gap. It is the gap that determines whether your mean-time-to-resolution is measured in minutes or hours. It is the gap that separates reactive, firefighting-mode operations from the predictive, self-correcting operations that enterprise scale demands.
Let us break down why this gap exists:
Cloud-Native Monitoring Creates Cloud-Specific Silos
Each provider's native monitoring is purpose-built for its own services, its own resource model, its own event taxonomy. They were never designed to correlate with each other.
When a customer transaction starts in an Azure-hosted front-end, hits an API on AWS, queries a database in your private data center, and returns through a CDN, no single native monitoring tool sees that full path. The Azure team sees the front-end latency. The AWS team sees the API timeout. The on-prem team sees the database load. But nobody sees the causal chain connecting all three. And in the time it takes three separate teams to coordinate, compare timestamps, and manually correlate events across three dashboards.
Organizational Silos Mirror Tool Silos
Your tool fragmentation is not a technology accident; it is a mirror of your organizational structure. Each silo is optimized locally, and nobody owns the cross-environment operational picture.
This is why simply "adding another monitoring tool" never solves the problem. You cannot fix an organizational intelligence gap with another dashboard. You fix it with an architecture that was designed, from the ground up, to operate across boundaries.
Data Gravity Makes Centralization Harder Than It Sounds
As your data volumes grow in each cloud environment, the cost and latency of moving that data elsewhere for analysis increases. Enterprises running AI and ML workloads are feeling this acutely, the compute must live where the data lives, and the data is increasingly distributed.
This means your AIOps solution cannot be a centralized monolith that requires all telemetry to be shipped to a single location. It needs to be architecturally distributed, capable of analyzing data where it lives and correlating insights across environments without requiring you to move petabytes of telemetry into a single data lake. This architectural requirement eliminates many legacy monitoring platforms from serious consideration.
Why AIOps Is Structurally Necessary for Hybrid and Multi-Cloud
If the previous section describes the problem, this section explains why AIOps is the structurally correct answer. And it comes down to three capabilities that no other approach can provide at scale:
Cross-Environment Event Correlation
In a hybrid environment, a single customer-impacting incident might generate alerts in five different tools across three environments. Five separate investigation threads. Five separate engineers chasing what turns out to be one root cause.
An AIOps correlation engine ingests events from all environments simultaneously, applies ML-driven pattern matching to identify that these five alerts share a common cause, and presents your operations team with one correlated incident instead of five. Research consistently shows that this kind of intelligent correlation achieves compression rates of 70–85% — meaning your team deals with 15–30 actionable incidents instead of 100 raw alerts.
Dynamic Topology Mapping Across Hybrid Infrastructure
In cloud-native environments, the topology is constantly changing. Containers spin up and down. Serverless functions execute and disappear. Auto-scaling groups expand and contract. The infrastructure you monitored five minutes ago may not exist anymore.
In a hybrid environment, this challenge is compounded by the fact that your topology spans environments that use fundamentally different resource models.
AIOps platforms with auto-discovery and topology mapping continuously scan across all environments, cloud and on-prem, to build and maintain a real-time, unified dependency map. When an incident occurs, this map shows exactly which services, applications, and business functions are affected, regardless of where they run.
Predictive Intelligence That Operates Across Silos
A capacity constraint building in your on-prem database, combined with a traffic surge being handled by your cloud-hosted front-end, might together predict a cascade failure that neither environment's monitoring would detect in isolation. Only an intelligence layer that sees both environments simultaneously and has historical context about how they interact can make that prediction.
This is why AIOps for hybrid and multi-cloud is not just "monitoring with AI added." It is a fundamentally different architectural approach, one that treats the entire hybrid estate as a single operational domain, regardless of where individual components are hosted.
The AIOps Architecture: Five Layers That Make It Work
Understanding AIOps architecture is critical for any technology leader evaluating solutions, because the architecture determines whether a platform will truly operate across your hybrid estate or simply aggregate dashboards from multiple sources. Those are very different capabilities, and confusing them is one of the most expensive mistakes enterprises make.
A production-grade AIOps architecture for hybrid and multi-cloud consists of five interdependent layers. Each layer builds on the one below it, and weakness in any layer undermines everything above:
| Architecture Layer | What It Does | Why It Matters for Hybrid/Multi-Cloud |
|---|---|---|
| Layer 1: Data Ingestion & Normalization | Collects metrics, logs, traces, events, and alerts from every source — AWS, Azure, GCP, on-prem, SaaS, network devices, containers, serverless. Normalizes diverse formats into a unified event model. | Without normalization, the same concept (e.g., "latency" or "CPU utilization") is described differently across providers. Correlation is impossible without a common language. |
| Layer 2: Unified Data Store | Stores structured and unstructured telemetry in a scalable data lake. Supports both real-time streaming and historical batch analysis. Retains context for trend analysis and seasonal pattern recognition. | Hybrid environments generate telemetry at massive scale. The data store must handle volume without becoming a bottleneck, and must support cross-environment queries natively. |
| Layer 3: Analytics & ML Engine | Applies machine learning for anomaly detection, event correlation, root cause analysis, predictive forecasting, and noise suppression. Uses supervised models for known failure patterns and unsupervised models for unknown anomalies. | This is the intelligence core. In hybrid environments, the ML models must learn cross-environment patterns — not just within-cloud behaviors — to detect cascading failures. |
| Layer 4: Automation & Orchestration | Executes remediation actions based on analytical insights: auto-scaling, traffic rerouting, service restarts, deployment rollbacks. Integrates with ITSM tools (ServiceNow, Jira) for ticket creation and routing. | Automation must operate across cloud APIs and on-prem infrastructure simultaneously. A remediation that works in AWS must also trigger corresponding actions in your data center if the incident spans both. |
| Layer 5: Visualization & Business Context | Presents unified dashboards, service maps, and topology views. Maps infrastructure events to business services and customer impact. Provides role-based views for different teams. | The unified topology map is what replaces the fragmented dashboards. IT leaders see business impact; engineers see technical root cause — from a single platform. |
The Critical Dependency: Each Layer Relies on the One Below
Here is the architectural insight that separates successful AIOps deployments from expensive failures: these layers are tightly coupled. Analytics quality is directly constrained by ingestion quality. Automation accuracy depends entirely on analytics accuracy. And visualization is only as useful as the intelligence feeding it.
If your data ingestion layer has gaps, if it cannot reach your on-prem infrastructure, or if it normalizes AWS events but not Azure events, then your analytics engine is performing pattern detection on an incomplete picture. The ML models learn the wrong patterns. The correlations are partial. And automation acts on flawed intelligence.
This is exactly why many enterprises report that AIOps was "challenging" or "very difficult" to implement. It is not because the AI is not smart enough. It is because the data foundation — Layer 1 and Layer 2 — was not designed for the hybrid complexity the platform was asked to manage.
Where Enterprises Go Wrong with Multi-Cloud AIOps
If you are considering AIOps for your hybrid environment (and the market data says you should be — the AIOps platform market is projected to grow from $21 billion in 2026 to over $73 billion by 2032), here are the most common mistakes we see enterprises make:
Treating AIOps as a Monitoring Upgrade
AIOps is not "monitoring with AI." It is a fundamentally different operational model. If you deploy an AIOps platform and continue operating with the same siloed teams, the same fragmented processes, and the same reactive incident response workflows, you will get marginal improvement at significant cost. AIOps requires cross-functional collaboration, unified processes, and organizational willingness to let automation handle what humans used to do manually.
Buying AIOps Before Fixing Data Quality
The analytics engine is only as good as the data feeding it. If your telemetry has gaps, inconsistent schemas, missing context, or siloed storage, the AI will learn the wrong patterns and produce unreliable correlations. Thoughtworks' 2025 analysis of enterprise AIOps deployments found that the implementations that failed did so because operational knowledge was not AI-ready — not because the AI lacked capability. Fix your data foundation first.
Ignoring Business Context
AIOps that only correlates infrastructure events misses half the picture. A sudden spike in traffic might look like an anomaly to the ML engine, but it is actually the expected result of a marketing campaign that launched an hour ago. Without business context (product launches, sales events, deployment schedules, customer communication), AIOps generates false positives on events that are perfectly normal. The most successful AIOps implementations connect infrastructure telemetry with business-side event feeds.
Trying to Automate Everything on Day One
Autonomous remediation is the ultimate goal, but it requires trust that is earned through demonstrated accuracy. Start with automated detection and correlation. Progress to automated ticket creation and enrichment. Then move to automated remediation for well-understood, low-risk incident types. Build governance and rollback capabilities before expanding the automation scope. Organizations that try to automate remediation before their correlation accuracy is proven end up automating mistakes at machine speed.
Underestimating the Compliance Dimension
In regulated industries, hybrid and multi-cloud operations face strict data sovereignty requirements. Some telemetry cannot leave certain geographic regions. Some audit trails must be maintained for years. Some automation actions require human approval before execution. Your AIOps architecture must accommodate these constraints — region-aware data processing, configurable approval workflows, and comprehensive audit logging are not optional features for enterprises in finance, healthcare, or government.
The AIOps Maturity Curve for Multi-Cloud Enterprises
Based on what we see across the industry, hybrid and multi-cloud enterprises typically move through four maturity stages on their AIOps journey. Understanding where you are on this curve determines what you should invest in next:
Siloed Monitoring (Where Most Enterprises Are Today)
Each cloud environment and on-prem system has its own monitoring tools. Alert volumes are high. Cross-environment incidents take hours to diagnose because teams must manually correlate data from multiple dashboards. The operations team is in constant reactive mode. The primary metric is MTTR, and it is measured in hours, not minutes.
Consolidated Visibility
Telemetry from all environments is ingested into a unified platform. Data is normalized. Teams can see a single dashboard that spans clouds and on-prem. Alert noise is reduced through basic deduplication and grouping. MTTR drops significantly, but root cause analysis still requires significant human effort.
Intelligent Operations
ML-driven correlation, anomaly detection, and root cause analysis are operational. Cross-environment incidents are automatically correlated into single incidents. Topology is auto-mapped and updated continuously. Predictive alerting catches capacity issues before they cause outages. Automation handles ticket creation, enrichment, and routing. MTTR is measured in minutes.
Autonomous Operations
Automated remediation handles well-understood incident types without human intervention. Self-healing workflows operate across cloud boundaries. The operations team shifts from incident response to system optimization. Business context is fully integrated, preventing false positives from planned events. The primary metric shifts from MTTR to incidents prevented.
Most enterprises today are between Stage 1 and Stage 2. The jump from Stage 2 to Stage 3 is where AIOps delivers its most dramatic returns — and it is where the architectural foundations described earlier in this blog become critical.
Where Heal Software Fits Into This Architecture
If you have followed this blog's argument, you understand that AIOps for hybrid and multi-cloud is not about adding another tool to your stack. It is about replacing the fragmented, siloed, cloud-specific monitoring approach with a unified intelligence architecture that was designed from the ground up to operate across boundaries.
That is exactly what Heal Software delivers. Our platform is built on the five-layer AIOps architecture described in this blog, with specific capabilities purpose-built for hybrid and multi-cloud enterprises:
- Unified Data Lake: Ingests telemetry from AWS, Azure, GCP, on-prem infrastructure, SaaS applications, network devices, and edge systems into a single, normalized data store. Every event, across every environment, speaks the same language.
- Cloud-Agnostic Agents & Agentless Discovery: Supports agent-based deep instrumentation where you need it and agentless discovery where you cannot or prefer not to install agents, covering legacy systems, network devices, and compliance-restricted environments.
- Cross-Cloud Event Correlation Engine: ML-driven correlation that understands cross-environment dependencies. Hundreds of alerts from multiple providers collapse into a handful of actionable, context-rich incidents. Noise reduction rates of 70–85%.
- Topology Auto-Mapping: Continuous, automated discovery that builds and maintains a real-time dependency map across your entire hybrid estate. No manual CMDB updates. No outdated topology diagrams. A living, accurate picture of how your systems connect.
- Cross-Environment Automated Remediation: Automation that operates across cloud APIs and on-prem management planes simultaneously. Configurable approval workflows for regulated environments. Full audit logging for compliance.
- Business Context Integration: Connects infrastructure intelligence to business events, deployment schedules, and customer impact metrics — so your AIOps does not just tell you what is broken, but who is affected and why it matters.
Seven Questions Every IT Leader Should Ask Before Choosing an AIOps Platform for Multi-Cloud
Whether you evaluate Heal Software or any other solution, these questions will separate platforms that genuinely operate across hybrid environments from those that simply claim to:
- Does the platform ingest from all of our environments natively or does it require third-party connectors and custom integrations? Native ingestion is faster to deploy, more reliable, and easier to maintain.
- Does the correlation engine understand cross-environment dependencies or does it just group alerts by time window? Topology-aware correlation is exponentially more accurate.
- Is the topology map auto-discovered and continuously updated, or does it rely on a manually maintained CMDB? In cloud-native environments, manual topology is always outdated.
- Can the automation engine execute remediation across cloud boundaries or only within a single provider? Multi-cloud incidents require multi-cloud remediation.
- How does the platform handle data sovereignty and regional compliance requirements? For regulated industries, this is non-negotiable.
- Can the platform incorporate business context (deployment schedules, marketing events, traffic forecasts) into its analytics? Without this, expect high false positive rates.
- What is the deployment timeline and what does the platform require from your team during implementation? Full enterprise AIOps deployments typically take 12–24 months for phased rollout. Platforms that promise otherwise are likely cutting corners on data quality.
The Bottom Line: Multi-Cloud Complexity Is Not Going Away. Your Operations Model Has to Evolve.
The hybrid cloud market is projected to reach $230 billion by 2032. Over 85% of enterprises already operate multi-cloud environments. The complexity of managing operations across these environments is growing faster than most IT organizations can staff for — the global IT skills gap is nearly 4.8 million professionals and widening.
The enterprises that thrive in this environment will not be the ones with the most monitoring tools. They will be the ones that built an intelligent, architecturally sound AIOps layer that treats their entire hybrid estate as a single operational domain — with unified ingestion, cross-cloud correlation, auto-mapped topology, predictive analytics, and automated remediation that operates across boundaries.
That is not a future aspiration. It is an architectural decision you can make today.
About HEAL Software
HEAL Software is a renowned provider of AIOps (Artificial Intelligence for IT Operations) solutions. HEAL Software's unwavering dedication to leveraging AI and automation empowers IT teams to address IT challenges, enhance incident management, reduce downtime, and ensure seamless IT operations. Through the analysis of extensive data, our solutions provide real-time insights, predictive analytics, and automated remediation, thereby enabling proactive monitoring and solution recommendation. Other features include anomaly detection, capacity forecasting, root cause analysis, and event correlation. With the state-of-the-art AIOps solutions, HEAL Software consistently drives digital transformation and delivers significant value to businesses across diverse industries.
Ready to see what this looks like in your environment?
HEAL Software helps IT leaders turn operational complexity into clarity, without adding to the stack.