
Why Alert Fatigue Is Killing Your MTTR
Published: April 22, 2026
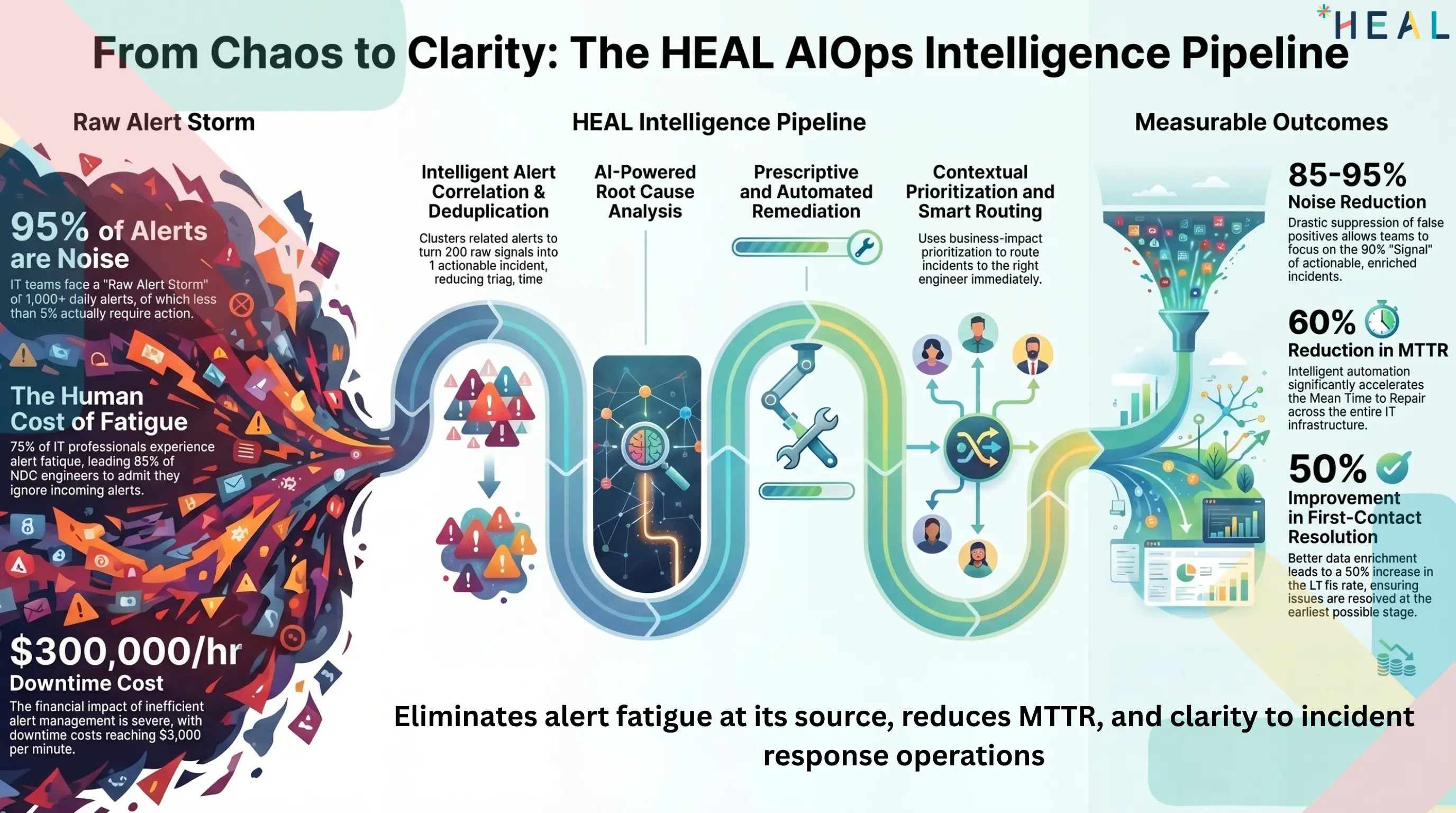
The Hidden Cost of Too Many Alerts
Every minute counts when production systems go down. Yet the average enterprise NOC team receives over 1,000 alerts per day, according to a 2025 study by OpsRamp. Of those, fewer than 5% require human intervention. The rest? They are noise — redundant, low-priority, or symptomatic signals that bury the genuine incidents demanding immediate attention.
This is alert fatigue: the progressive desensitization of IT operations teams caused by an unrelenting flood of monitoring notifications. It does not merely slow response times; it fundamentally erodes the operational resilience that modern digital enterprises depend on. When engineers begin ignoring alerts because experience has taught them that most are irrelevant, critical production incidents slip through the cracks, and Mean Time to Resolution (MTTR) spirals upward.
The consequences are quantifiable and severe. Gartner estimates that the average cost of IT downtime is $5,600 per minute, roughly $300,000 per hour. For organizations where alert fatigue is adding 15 to 30 minutes to every major incident's resolution timeline, the annual financial exposure can reach millions of dollars, to say nothing of the reputational damage and customer attrition that follow prolonged outages.
The Anatomy of Alert Fatigue: Why Traditional Monitoring Fails
Alert fatigue is not a people problem. It is a systems problem. Modern IT environments have grown exponentially in complexity. A mid-sized enterprise today operates across hybrid cloud architectures, microservices meshes, containerized workloads, edge computing nodes, and legacy on-premises systems, each layer instrumented with its own monitoring stack. The result is an avalanche of observability data that traditional threshold-based alerting was never designed to handle.
The Numbers Tell the Story
- 78% — of IT operations professionals report experiencing alert fatigue (PagerDuty State of Digital Operations, 2025)
- 45% — of all monitoring alerts are false positives or duplicates (Everest Group, 2025)
- 30% — increase in MTTR attributed to alert noise in enterprise environments (IDC, 2025)
- 62% — of NOC engineers admit to ignoring or deprioritizing alerts they suspect are non-critical (BigPanda, 2024)
These are not marginal inefficiencies. They represent a systemic failure in how enterprises consume and act on operational intelligence. When nearly two-thirds of your frontline engineers acknowledge that they routinely dismiss alerts, the monitoring infrastructure is no longer a safety net, it is a liability.
How Alert Fatigue Directly Inflates MTTR
MTTR — Mean Time to Resolution — is the North Star metric for IT operations maturity. It measures the elapsed time from incident detection to full service restoration. Alert fatigue attacks every stage of this lifecycle.
1. Delayed Detection
When genuine alerts are buried in thousands of low-priority notifications, the time between an incident occurring and an engineer actually noticing it grows significantly. Research from Splunk's 2025 State of Observability report found that organizations with high alert volumes take an average of 12 minutes longer to detect critical incidents compared to those with optimized alerting pipelines. In a world where every minute of downtime costs thousands of dollars, this detection lag alone can represent six-figure losses per incident.
2. Prolonged Triage
Once an alert is noticed, the engineer must determine its severity, scope, and ownership. In a noisy environment, this triage phase expands dramatically. Engineers cross-reference multiple dashboards, correlate timestamps across disparate tools, and attempt to distinguish root causes from downstream symptoms, all manually. A 2024 Forrester study found that IT teams spend an average of 25 minutes per incident on triage activities that could be automated, with alert-fatigued teams spending up to 40 minutes.
3. Misrouted Escalations
Alert fatigue does not just slow response, it misdirects it. When Level 1 teams cannot confidently assess an alert's severity, they either escalate prematurely (flooding senior engineers with low-priority tickets) or too late (allowing critical issues to fester). Everest Group's 2025 analysis found that 35% of escalations in alert-fatigued environments are unnecessary, consuming senior engineering bandwidth and delaying resolution of genuine P1 incidents.
4. Cognitive Overload and Human Error
The psychological toll is real and measurable. Engineers operating under constant alert bombardment experience decision fatigue, a well-documented cognitive phenomenon where the quality of decisions deteriorates after a sustained period of decision-making. A 2025 study published in the Journal of Systems and Software found that incident responders who process more than 50 alerts per shift make 23% more diagnostic errors than those with optimized alert loads. These errors compound MTTR by introducing false starts, incorrect remediation attempts, and rollback cycles.
Why Threshold-Based Alerting and Manual Runbooks Cannot Solve This
Many organizations attempt to address alert fatigue through incremental tuning: adjusting thresholds, suppressing known noisy alerts, or building more elaborate runbooks. These efforts, while well-intentioned, treat symptoms rather than causes.
- Static thresholds cannot adapt to dynamic environments. A CPU utilization spike to 85% might be perfectly normal during a batch processing window but critical during peak transaction hours. Threshold-based systems lack the contextual intelligence to distinguish between these scenarios.
- Suppression rules create blind spots. Suppressing a frequently noisy alert source risks hiding a genuine failure when that source eventually produces a real incident. The 2024 PagerDuty post-incident analysis database revealed that 18% of major outages involved alerts that had been suppressed based on historical noise patterns.
- Manual correlation does not scale. As infrastructure complexity grows linearly, the number of potential alert correlations grows exponentially. A team of ten engineers cannot manually correlate alerts across 500 microservices, 50 Kubernetes clusters, and three cloud providers in real time.
- Runbook fatigue compounds alert fatigue. When engineers must consult lengthy, static runbooks for every alert, the cognitive overhead multiplies. Outdated runbooks, a pervasive problem, with 40% of enterprise runbooks found to be outdated or inaccurate according to a 2025 Gartner survey, introduce additional diagnostic errors.
The fundamental issue is architectural. Legacy monitoring was designed for monolithic, relatively static environments. Modern IT demands an approach that can ingest, correlate, and prioritize signals across the full technology stack in real time, using machine intelligence rather than human bandwidth.
How HEAL Software Eliminates Alert Fatigue and Restores MTTR
HEAL Software is an enterprise-grade AIOps platform purpose-built to solve the alert fatigue crisis at its root. Rather than layering band-aid logic on top of legacy monitoring, HEAL reimagines the entire alerting pipeline through AI-driven correlation, intelligent suppression, automated root cause analysis, and prescriptive remediation.
Intelligent Alert Correlation and Deduplication
HEAL's correlation engine ingests alerts from across your entire technology stack — infrastructure, applications, network, cloud, databases, and security tools — and applies machine learning-driven topology mapping to identify relationships between alerts. Instead of presenting 200 individual alerts for a cascading database failure, HEAL consolidates them into a single, enriched incident with full dependency context.
The impact is dramatic. HEAL customers consistently report 85% to 95% alert noise reduction within the first 30 days of deployment. For a team receiving 1,000 alerts per day, that translates to fewer than 150 actionable signals, each enriched with contextual intelligence that accelerates triage from minutes to seconds.
AI-Powered Root Cause Analysis
Identifying that something is wrong is only half the battle. Engineers need to know why. HEAL's root cause analysis engine leverages historical incident patterns, real-time topology data, and anomaly detection algorithms to pinpoint the probable root cause of an incident within seconds of detection. This eliminates the manual "war room" diagnostic process that traditionally consumes 30 to 60 minutes of every major incident's resolution timeline.
In benchmark deployments, HEAL has demonstrated a 60% reduction in MTTR by compressing the detection-to-diagnosis phase from an average of 45 minutes to under 10 minutes.
Prescriptive and Automated Remediation
HEAL goes beyond diagnosis to prescribe and, where authorized, execute remediation actions. The platform's remediation engine draws on a continuously updated knowledge base of resolution patterns, organizational runbooks, and industry best practices to recommend specific corrective actions for each incident type. For pre-approved scenarios, HEAL can execute remediation autonomously, reducing human involvement to post-incident review.
This capability is particularly transformative for recurring incidents. HEAL's data shows that 40% of production incidents are repeat occurrences of known issues. By automating the resolution of these recurring events, HEAL frees engineering capacity for strategic work while simultaneously eliminating the MTTR contribution of repetitive troubleshooting.
Contextual Prioritization and Smart Routing
Not all incidents are created equal, and HEAL's prioritization engine ensures they are never treated as such. By correlating alert data with business impact metrics — transaction volumes, revenue exposure, SLA contractual obligations, and customer-facing service dependencies — HEAL dynamically assigns priority scores that reflect actual business risk rather than arbitrary severity labels.
Smart routing ensures that each prioritized incident reaches the right team and the right engineer based on skills, availability, and historical resolution effectiveness. This eliminates the escalation ping-pong that plagues alert-fatigued environments and ensures that P1 incidents receive immediate attention from the most qualified responders.
Measurable Outcomes: What HEAL Delivers
The impact of deploying HEAL Software is quantifiable and consistently validated across enterprise deployments:
- 85–95% reduction in alert noise, transforming thousands of daily alerts into dozens of actionable, enriched incidents
- 60% reduction in MTTR, compressing the full incident lifecycle from detection through resolution
- 40% reduction in escalation volume, ensuring senior engineers focus on genuinely complex problems
- 50% improvement in first-contact resolution rates at Level 1, enabled by AI-driven diagnostic guidance
- 30% reduction in operational costs through automation of repetitive incident response tasks
- Measurable improvement in engineer satisfaction and retention, addressing the burnout and attrition crisis that alert fatigue accelerates
These are not aspirational projections. They are outcomes consistently achieved by HEAL customers across financial services, healthcare, telecommunications, retail, and technology sectors.
The Strategic Imperative: Why Addressing Alert Fatigue Cannot Wait
Alert fatigue is not a problem that resolves itself. As enterprises continue to adopt cloud-native architectures, expand their digital footprints, and integrate AI-driven workloads, the volume and complexity of operational signals will only increase. Organizations that fail to modernize their alerting and incident response capabilities will face compounding consequences:
- Accelerating MTTR degradation as infrastructure complexity outpaces human capacity
- Rising operational costs as teams grow to compensate for inefficient processes
- Increasing talent attrition as skilled engineers leave burnout-inducing environments
- Growing business risk as digital services become more critical to revenue and customer experience
The organizations that will thrive are those that recognize alert fatigue as a strategic infrastructure challenge, not merely an operational annoyance — and invest in AI-driven platforms capable of transforming raw observability data into actionable operational intelligence.
Take Control of Your Alert Pipeline With HEAL Software
HEAL Software is the enterprise AIOps platform that eliminates alert fatigue at its source, reduces MTTR by 60%, and restores confidence and clarity to your incident response operations. Whether you are managing a hybrid cloud environment, a complex microservices architecture, or a global multi-data-center deployment, HEAL delivers the intelligent correlation, automated diagnosis, and prescriptive remediation that modern IT operations demand.
About HEAL Software
HEAL Software is a renowned provider of AIOps (Artificial Intelligence for IT Operations) solutions. HEAL Software's unwavering dedication to leveraging AI and automation empowers IT teams to address IT challenges, enhance incident management, reduce downtime, and ensure seamless IT operations. Through the analysis of extensive data, our solutions provide real-time insights, predictive analytics, and automated remediation, thereby enabling proactive monitoring and solution recommendation. Other features include anomaly detection, capacity forecasting, root cause analysis, and event correlation. With the state-of-the-art AIOps solutions, HEAL Software consistently drives digital transformation and delivers significant value to businesses across diverse industries.
Ready to see what this looks like in your environment?
HEAL Software helps IT leaders turn operational complexity into clarity, without adding to the stack.