
AIOps Use Cases for IT Operations: What It Solves in Enterprise IT
by Renuka Suresh | Jan 06, 2026

Core thesis: AIOps solves the enterprise gap between telemetry volume and operational decisions by converting noisy signals into prioritized incidents with probable causality, so recovery gets faster and repeat failures stop.
The Real Problem: Observability Without Operational Intelligence
Your monitoring stack produces telemetry. Logs stream at 400GB per day. APM tools track latency across 18 microservices. Infrastructure metrics flood dashboards every 15 seconds. You have observability, comprehensive visibility into system state.
What you don't have is operational intelligence: the ability to determine what matters right now, why it's happening, and what prevents it from recurring.
The delta between these two states is where enterprises lose hours during incidents and why the same database connection pool exhaustion happens quarterly. Monitoring tells you a threshold broke. While AIOps tells you the payment gateway is down because the authentication service scaled unevenly after the 2AM deployment, this is the third time this specific dependency chain has caused customer impact.
That distinction between alert volume and decision-grade intelligence is what AIOps platforms are built to close.
AIOPS Use Case 1: Event Correlation Across Siloed Telemetry Sources
The operational gap: A checkout failure in production triggers 47 alerts across Datadog, Splunk, PagerDuty, and your ITSM tool within 90 seconds. Your on-call engineer receives notifications from three channels simultaneously. Which alert represents the root cause? Which seventeen are symptoms? The engineer spends 12 minutes correlating timestamps, tracing dependencies manually, and ruling out false positives before even starting remediation.
What HEAL AIOps solve: Correlation engines ingest events from heterogeneous sources, normalize timestamps and metadata, then apply temporal and topological analysis to correlate related alerts into a single incident with ranked probable causes. The same 47 alerts become one incident tagged with "API gateway timeout" as primary signal and "upstream database saturation" as contributing factor.
Topology awareness is critical here. HEAL AIOps platform maintains a service dependency graph often learned from traffic patterns rather than manually configured so when an alert fires in the authentication layer, the correlation engine already knows which downstream services will cascade failures. Alerts aren't just grouped by time proximity; they're weighted by dependency relationships and historical co-occurrence patterns.
Measurable outcome: Enterprises typically see alert noise reduction between 60-85% after correlation tuning. More importantly, MTTR (mean time to resolution) drops by 30-50% because engineers start diagnosis with a ranked hypothesis rather than raw alert lists.
Why it matters to the IT Team: You already paid for observability tools. AIOps makes that investment operationally useful by turning signals into decisions. Every incident that resolves 20 minutes faster is customer impact you avoided and engineering capacity you reclaimed.
AIOPS Use Case 2: Anomaly Detection That Understands Normal Is Dynamic
The operational gap: Static thresholds fail in elastic infrastructure. CPU at 75% is normal during batch processing windows but critical during checkout traffic. A human-tuned alert either fires constantly (alert fatigue) or misses genuine degradation (missed SLA breaches). Your team adjusts thresholds quarterly, but seasonal traffic patterns and feature releases keep invalidating those baselines.
What HEAL AIOps solve: Behavioral anomaly detection builds dynamic baselines per metric, per service, per time window. Machine learning models learn that Friday evening API latency sits at p95 = 240ms while Tuesday morning runs at p95 = 95ms, and both are normal. When Friday evening latency hits 320ms, the model flags deviation from expected behavior, not deviation from a static number.
Context matters. HEAL AIOps platform correlates anomalies with deployment events, infrastructure changes, and external dependencies. If S3 latency spikes and your upload service simultaneously shows increased error rates, the anomaly detector surfaces both signals together with the probable causal relationship not as two separate incidents.
Advanced implementations use unsupervised learning to detect unknown failure modes: patterns that don't match any historical incident but deviate from learned normal behavior. This catches novel degradation on the edge in case your runbooks haven't been documented yet.
Measurable outcome: Reduction in false positive alerts by 40-70% as dynamic baselines replace static thresholds. Earlier detection of capacity exhaustion and performance degradation before customer-facing impact, typically earlier than threshold-based alerts would fire.
Why it matters to the IT Team: False positives erode on-call engineer trust and response speed. When 70% of pages are noise, your team stops treating alerts as urgent. Dynamic anomaly detection restores signal quality, which directly improves incident response discipline.
AIOPS Use Case 3: Root Cause Inference Through Causal Graph Analysis
The operational gap: Post-incident reviews consume four engineer hours to reconstruct what happened. You have the timeline, the alerts, the metrics but determining causality requires manual analysis of dependency chains, reviewing deployment logs, and correlating external events. Six hours after resolution, you understand the proximate cause but not the contributing factors that let it escalate.
What HEAL AIOps solves: Causal inference analyzes incident topology and temporal sequences to propose probable root causes ranked by likelihood. When an incident occurs, the engine traces backwards through the graph, weighing which upstream change or failure could propagate to create the observed symptom pattern.
The platform learns causality over time. If database query timeout consistently appears upstream of API gateway errors, the model strengthens that causal edge. If load balancer configuration changes frequently precede traffic distribution anomalies within 10 minutes, that pattern gets encoded.
Measurable outcome: Post-incident analysis time drops from 3-5 hours to 45-90 minutes because causal hypotheses are pre-ranked. Repeat incident rates decrease by 25-40% as teams address root causes rather than proximate triggers.
Why it matters to the IT Team: Incident cost isn't just downtime; it's the engineering hours spent investigating plus the opportunity cost of delaying feature work. Root cause inference converts investigation from manual forensics into guided analysis. That efficiency compounds: faster incident resolution means more capacity for reliability improvements that prevent future incidents.
AIOPS Use Case 4: Predictive Failure Detection and Capacity Planning
The operational gap: Your database crashes at 3AM because connection pool exhaustion reached critical threshold. Monitoring showed gradual connection count increase over six hours, but no alert fired because the rate of change was below threshold. By the time the pool saturated, customer transactions were already failing. Reactive alerting can't prevent failures; it only reports them after impact.
What HEAL AIOps solves: Predictive analytics is time-stamp-series forecasting resource utilization patterns and failure of precursors. Models learn that when database connection lifetime decreases while query latency increases over a 90-minute window, connection pool exhaustion follows within 30-45 minutes. The platform alerts while utilization sits at 68% below static threshold but on trajectory toward saturation.
Capacity prediction extends this forward. HEAL AIOps platform models resource consumption trends against upcoming load forecasts (seasonal traffic, scheduled campaigns, historical growth rates) to identify when current capacity will exhaust. Instead of discovering you need additional RDS capacity during Black Friday load, the system flags the gap three weeks prior with projected exhaustion date and recommended scaling action.
Pattern recognition identifies degradation signatures. Some failures announce themselves through subtle changes in memory leak patterns, gradual disk I/O saturation, increasing garbage collection pause times. Machine learning models detect these precursor patterns even when individual metrics remain within acceptable ranges.
Measurable outcome: Reduction in unplanned outages by 20-35% through early intervention before failure impact. Capacity planning cycles shift from reactive (post-incident scaling) to proactive (scheduled capacity addition), reducing emergency infrastructure costs by 15-25%.
Why it matters to the IT Team: Preventing an outage is 10x more valuable than fast recovery. Predictive detection converts operational posture from reactive firefighting to proactive risk mitigation. Every prevented incident is customer trust maintained and revenue protected.
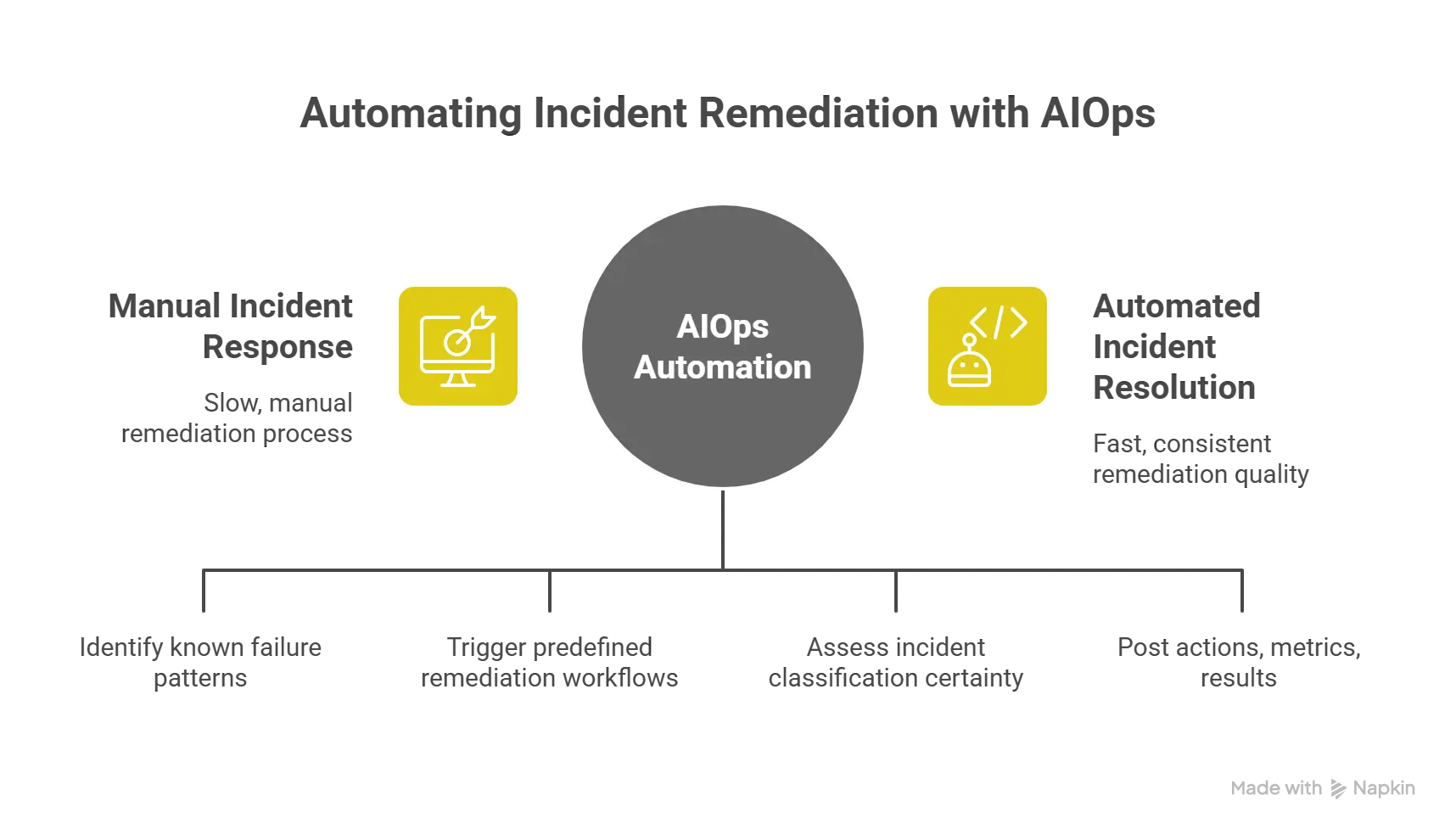
AIOPS Use Case 5: Automated Remediation and Runbook Execution
The operational gap: Your team documents remediation procedures for known failure modes. Runbooks exist for database failover, cache clearing, pod restarts, and traffic rerouting. But incident response still requires an engineer to diagnose the problem, locate the correct runbook, execute steps manually, and verify resolution. For a known issue with a documented fix, you're still paying 15-20 minutes of human latency plus on-call interruption cost.
What HEAL AIOps solves: Closed-loop automation connects incident detection to remediation execution. When the platform identifies a known failure pattern with database connection saturation matching historical signature, it will trigger predefined remediation workflows. The system executes the runbook: scales connection pool capacity, terminates long-running queries, alerts secondary on-call if remediation fails.
The critical distinction from simple automation is conditional execution based on diagnostics. HEAL AIOps platform doesn't just trigger scripts on alerts; it assesses incident classification certainty, verifies remediation prerequisites, and halts if conditions don't match expected patterns. This prevents automation from amplifying novel failures.
Integration with ChatOps and collaboration platforms closes the loop. Automated remediation posts actions taken, metrics affected, and verification results directly into incident channels, so on-call engineers maintain visibility even when automation handles resolution.
Measurable outcome: MTTR improvement of 40-60% for known, automatable incident classes. On-call interruption reduction by 30-45% as low-severity, repetitive incidents resolve automatically. Most critically, consistent remediation quality automation doesn't skip steps or misapply fixes under pressure.
Why it matters to the IT Team: Engineer time is your scarcest operational resource. Automated remediation reallocates that capacity from repetitive incident response to preventive reliability work. On-call quality improves, especially fewer pages for issues that should resolve automatically which directly impacts retention of senior operational talent.
The Implementation Reality: Not Plug-and-Play
The HEAL AIOps platform requires operational investment before delivering operational intelligence. The technology isn't turnkey; it's a capability layer that demands tuning, training data, and integration of work.
Topology discovery takes time. Accurate service dependency mapping requires weeks of traffic analysis or manual configuration. Without correct topology, correlation produces groupings that don't reflect actual causal relationships.
Model training needs historical data. Anomaly detection requires 30-90 days of baseline data per metric to learn normal behavior patterns. Seasonal businesses need full-year data sets to capture cyclical patterns. Initial deployment accuracy is lower until models stabilize.
Integration complexity scales with tool sprawl. If you're ingesting from twelve different monitoring systems, each integration requires API mapping, authentication configuration, and data normalization. The more heterogeneous your telemetry sources, the longer it takes to achieve clean correlation.
False positive tuning is iterative. Initial deployments often over-alert or misclassify incidents. Tuning confidence thresholds, adjusting correlation time windows, and refining causal edge weights requires operational feedback loops over multiple incident cycles.
The enterprises that succeed treat AIOps deployment as a 6-12 month operational maturity program, not a software installation. Start with a single high-noise domain maybe your Kubernetes infrastructure or your API gateway layer, tune correlation and anomaly detection there, prove value, then expand coverage.
Decision Framework: When AIOps Solves Actual Problems
AIOps makes sense when you have specific operational pain that observability alone can't fix:
- You're drowning in alerts. If on-call engineers spend more time correlating alerts than remediating problems, correlation intelligence delivers immediate value.
- Repeat incidents consume disproportionate time. If the same failure modes recur quarterly because post-incident analysis never surfaces true root causes, causal inference addresses that gap.
- Your infrastructure outgrew static monitoring. If you operate elastic infrastructure where "normal" changes hourly and static thresholds generate constant false positives, dynamic anomaly detection restores signal quality.
- You have documented runbooks that aren't executed consistently. If remediation procedures exist but incident response quality varies by which engineer is on-call, automation standardizes execution.
AIOps doesn't solve observability gaps, it solves operational intelligence gaps. If you can't answer "what's happening right now" because you lack telemetry coverage, buy better monitoring first. If you can answer "what's happening" but can't answer "why it matters, what caused it, and how we stop it recurring," that's where AIOps platforms create value.
The Operational Layer You're Actually Funding
When you budget for AIOps, you're not buying another monitoring dashboard. You're funding an operational intelligence layer that sits between your telemetry infrastructure and your incident response processes.
That layer converts signals into decisions: which alert deserves immediate attention, what the probable root cause is, whether this incident matches a known pattern with defined remediation, and which contributing factors enable recurrence.
The business case isn't abstract cost reduction; it's specific operational improvements with measurable impact. Faster incident resolution protects revenue and customer trust. Reduced false positive rate improves on-call engineer effectiveness and retention. Root cause intelligence prevents repeat failures that compound operational debt.
The question isn't whether AIOps delivers value; it's whether your operational maturity and tool sprawl have reached the threshold where correlation, causality, and automation deliver more value than their implementation cost.
For most enterprises operating distributed systems at scale with heterogeneous monitoring stacks and recurring operational pain from alert noise and repeat incidents, that threshold arrived two years ago.
About HEAL Software
HEAL Software is a renowned provider of AIOps (Artificial Intelligence for IT Operations) solutions. HEAL Software’s unwavering dedication to leveraging AI and automation empowers IT teams to address IT challenges, enhance incident management, reduce downtime, and ensure seamless IT operations. Through the analysis of extensive data, our solutions provide real-time insights, predictive analytics, and automated remediation, thereby enabling proactive monitoring and solution recommendation. Other features include anomaly detection, capacity forecasting, root cause analysis, and event correlation. With the state-of-the-art AIOps solutions, HEAL Software consistently drives digital transformation and delivers significant value to businesses across diverse industries.