
How Overlooked Anomalies Can Lead to Enterprise Losses
by Raja Shekar Mulpuri | Jan 20, 2025

Organizations invest heavily in robust systems, talented personnel, and sophisticated tools to ensure smooth operations. Yet, small anomalies often escape attention—minor glitches in applications, occasional lags in processes, or subtle irregularities in performance metrics. These may appear insignificant, but when left unaddressed, they can cascade into significant disruptions, leading to operational inefficiencies, financial losses, and reputational damage.
The Domino Effect of Overlooked Anomalies
A small irregularity in one part of an enterprise system might initially appear inconsequential—a delayed API response, a misconfigured server setting, or a minor discrepancy in data synchronization. However, these small issues often follow the principle of compounding effects, where minor faults escalate as they propagate across interconnected systems. Consider the following scenarios:
- Subtle Performance Drops: A 2% increase in page load time may not raise alarms initially. However, if the delay is consistent, it can lead to higher bounce rates, reduced user engagement, and ultimately, revenue loss for e-commerce platforms.
- Data Integrity Errors: A small error in data migration or synchronization may go unnoticed initially. Over time, such errors can corrupt analytics insights, leading to flawed business decisions.
- Systemic Overload: A misconfigured database query causing minor lags might strain the system under peak loads, leading to outages that impact critical operations.
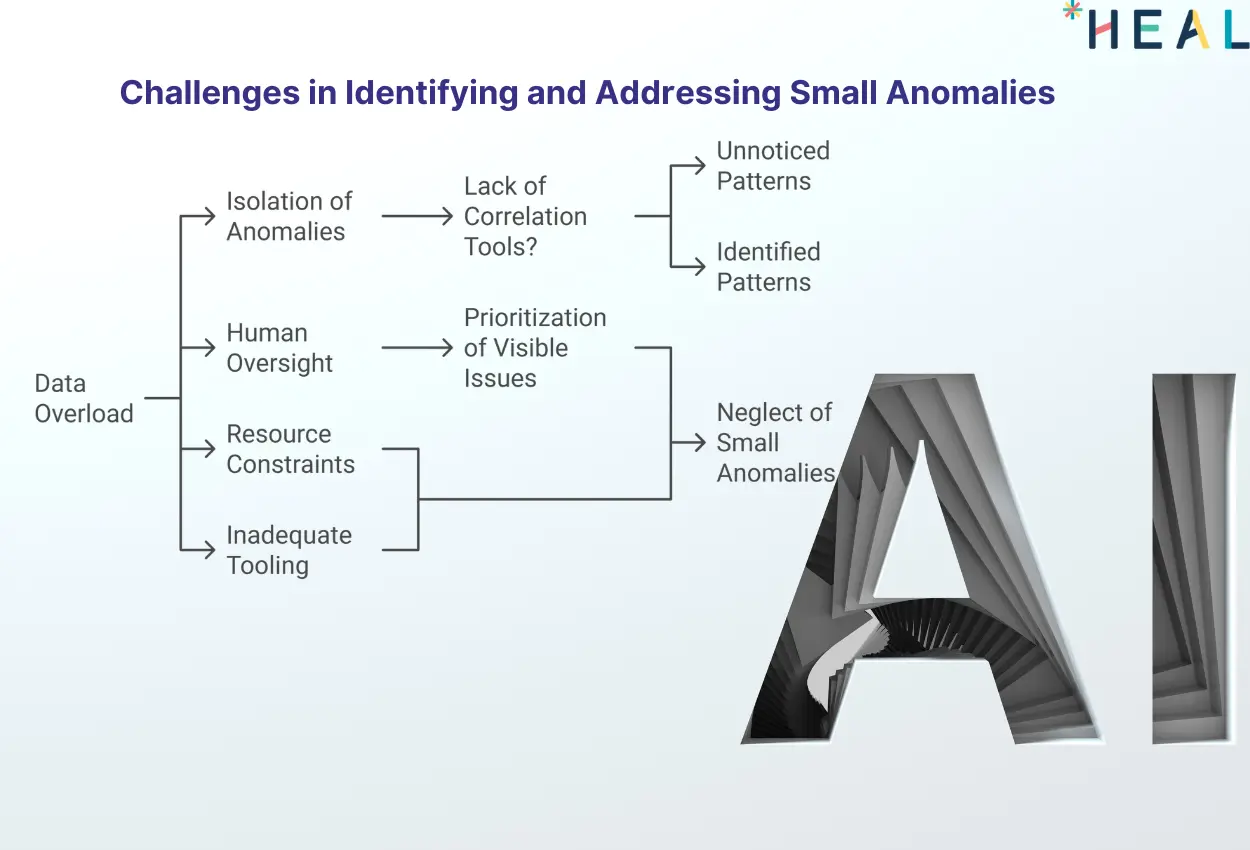
Challenges in Identifying and Addressing Small Anomalies
Volume and Complexity of DataEnterprises generate massive amounts of data daily. Sifting through logs, metrics, events, and traces (MELT) to identify small but meaningful anomalies is akin to finding a needle in a haystack. This data overload often results in minor issues being buried under layers of information.
Lack of Contextual CorrelationSmall anomalies in isolation often appear harmless. Without tools to correlate these anomalies across systems, teams struggle to identify patterns or understand their broader impact. For instance, a minor network latency issue might go unnoticed until it affects database performance downstream.
 Human Oversight
Human Oversight
Manual monitoring relies heavily on human judgment, which is prone to error. Teams may prioritize visible issues or those with immediate impact, sidelining small anomalies that could have long-term repercussions.
Resource ConstraintsMonitoring every minor irregularity requires resources that many enterprises can’t spare. Prioritizing high-impact areas often leads to neglect in less visible parts of the system, where small issues can fester.
Inadequate ToolingTraditional monitoring tools often operate in silos, lacking the sophistication to detect and analyze interconnected anomalies. This limitation results in blind spots, where small issues go unnoticed until they escalate.
The Cost of Neglect
Financial ImpactUnresolved small issues can lead to downtime, productivity loss, and increased operational costs. Gartner estimates that the average cost of IT downtime is $5,600 per minute, with cumulative annual losses reaching millions for enterprises.
Reputational DamageEnd-users have little tolerance for performance issues. Frequent lags, glitches, or system outages can erode customer trust, leading to churn and negative reviews that damage brand reputation.
 Operational Inefficiencies
Operational Inefficiencies
Small anomalies, when compounded, can lead to inefficiencies across departments. For example, recurring delays in data processing can disrupt workflows, delaying project timelines and affecting overall productivity.
Missed OpportunitiesFlawed analytics or delayed insights caused by data anomalies can result in missed business opportunities, such as failing to capitalize on market trends or optimize supply chain operations.
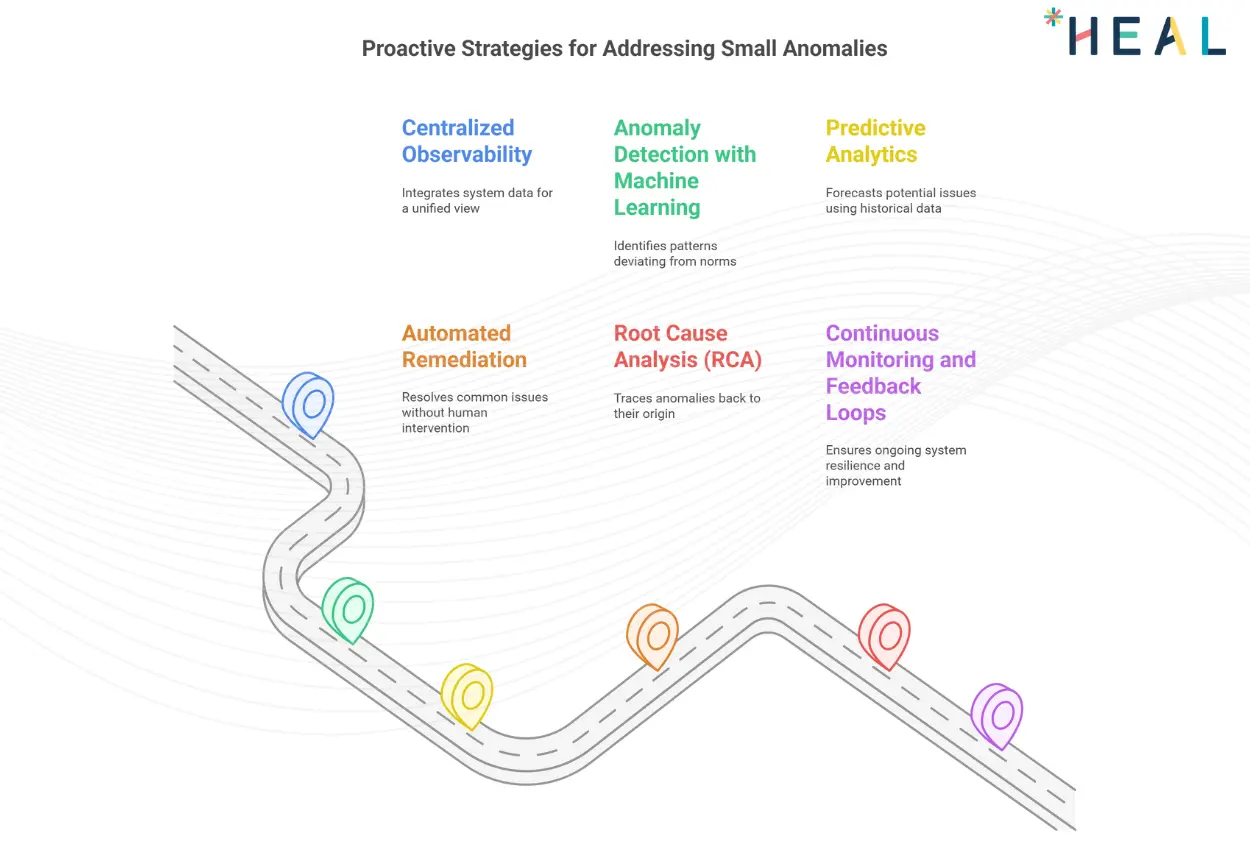
Strategies to Address Small Anomalies Proactively
Centralized ObservabilityCentralized observability platforms integrate logs, metrics, events, and traces (MELT) across systems, providing a unified view of system health. This allows teams to detect anomalies in real time and understand their root causes in context.
Anomaly Detection with Machine LearningAdvanced anomaly detection models use machine learning to identify patterns that deviate from the norm. These models can detect subtle issues that might escape human observation, such as gradual performance degradation or unusual usage patterns.
Predictive AnalyticsPredictive analytics leverages historical data to forecast potential issues before they occur. For example, predicting when server load might exceed capacity allows teams to take preemptive action, avoiding outages.
 Automated Remediation
Automated Remediation
Automation tools can resolve common issues without human intervention. For instance, if an application exceeds CPU usage thresholds, an automated system can spin up additional resources to stabilize performance.
Root Cause Analysis (RCA)Efficient RCA tools can trace anomalies back to their origin, allowing teams to address the root cause rather than treating symptoms. This prevents recurrence and ensures long-term system health.
Continuous Monitoring and Feedback LoopsImplementing continuous monitoring with feedback loops ensures anomalies are not only detected but also used to improve system resilience. Lessons learned from past issues can inform better configurations and preventive measures.
Market Insights: The Growing Importance of Anomaly Management
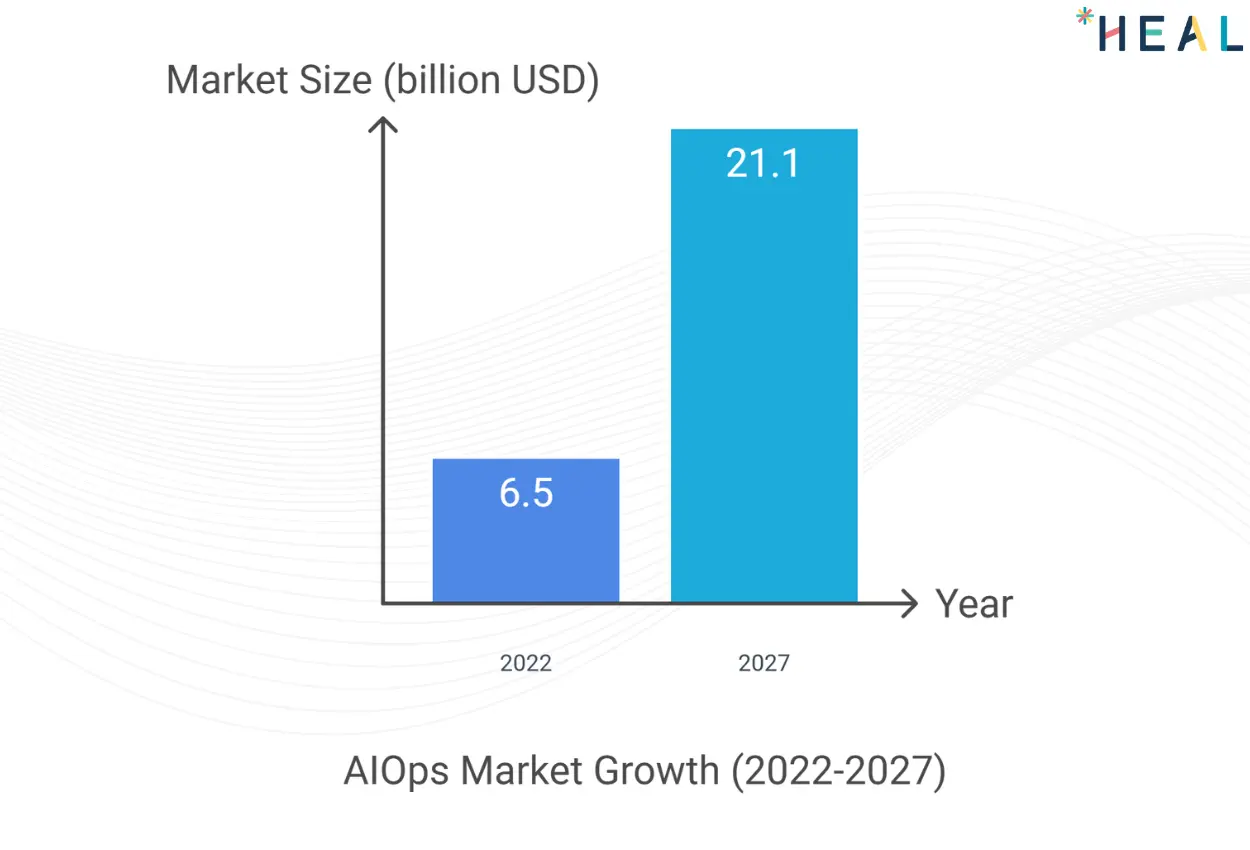
Global Trends in IT OperationsAccording to a study by MarketsandMarkets, the AIOps (Artificial Intelligence for IT Operations) market is expected to grow from $6.5 billion in 2022 to $21.1 billion by 2027. This growth underscores the increasing reliance on intelligent solutions to manage complex IT environments.
 Enterprise Adoption
Enterprise Adoption
A survey by Forrester reveals that 62% of enterprises struggle with managing anomalies in their IT infrastructure. Among these, organizations adopting advanced monitoring and predictive tools reported a 40% reduction in downtime and a 35% increase in operational efficiency.
The Cost of InactionThe Ponemon Institute’s research highlights that organizations without proactive anomaly management frameworks incur 30% higher costs due to system failures compared to those with advanced monitoring solutions.
Building Resilience: AIOps as the Solution
- Identifying Minor Issues Early: By detecting small anomalies in real time, AIOps prevents them from escalating.
- Providing Context: Correlating data across systems to understand the broader impact of issues.
- Automating Responses: Resolving repetitive issues without manual intervention
- Delivering Insights: Offering actionable recommendations for long-term system improvements
Use Case: Resolving High Memory Utilization for a Global Bank
A leading multinational bank, with 2,000 branches, 2,886 ATMs, and over 25 million users, faced a recurring issue of high memory utilization in their core banking applications powered by Infosys Finacle. Despite handling 393 million transactions annually with support from IT operations teams and infrastructure vendors, the bank struggled to identify the root cause of this anomaly. Initially, the memory issue appeared infrequent and didn’t impact daily operations. However, as it became more frequent over months, it began posing risks of operational instability, leading to 47+ hours of downtime per month and costing $11.5 million monthly.
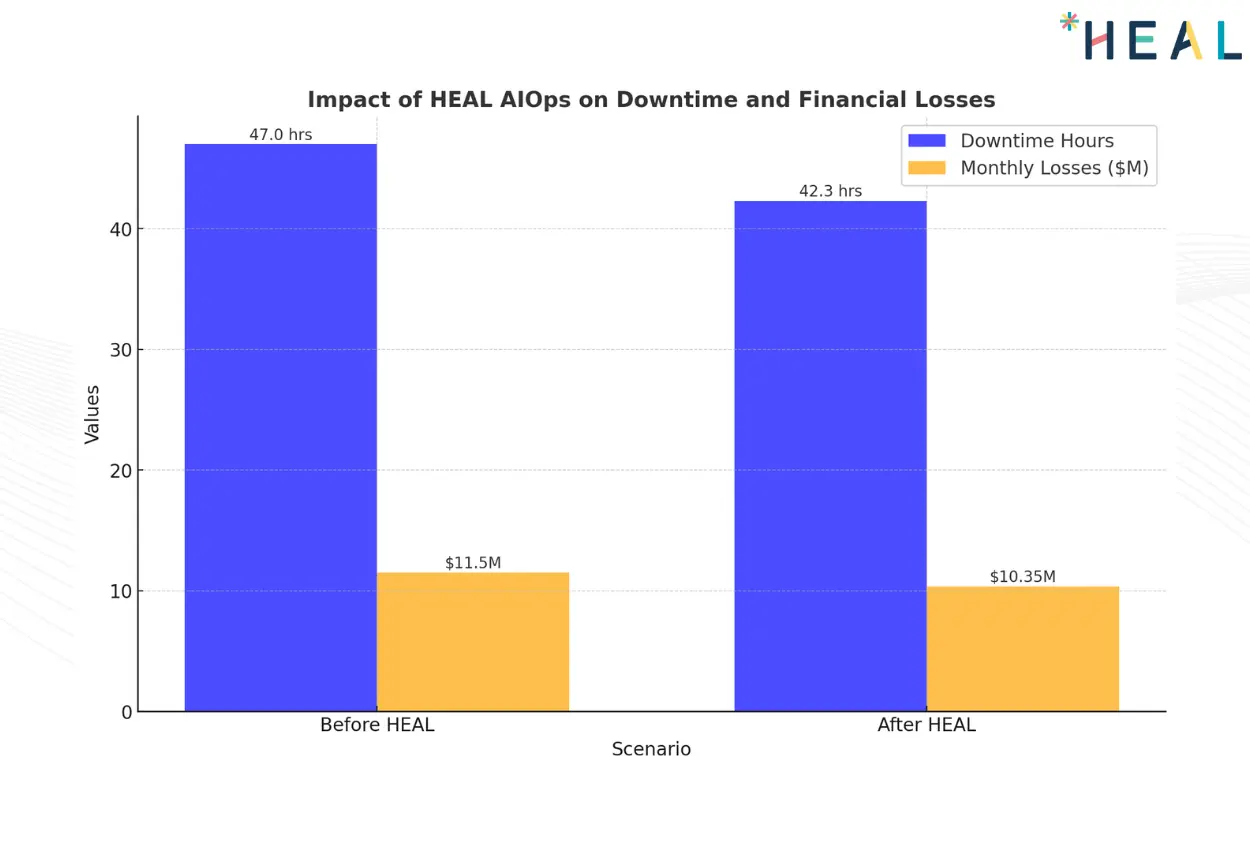
HEAL Software’s AIOps solution was deployed to address this challenge. Using advanced anomaly detection and root cause analysis, HEAL identified misconfigurations in application parameter values causing the memory spikes. With HEAL’s recommendations, the bank optimized the settings, reducing memory consumption and preventing future disruptions. HEAL’s proactive monitoring and predictive insights resulted in a 10% month-on-month reduction in outages, ensuring operational stability while saving millions in potential losses.
Small anomalies in enterprise systems are not trivial. Like a slow leak in a dam, they may initially seem negligible but can lead to catastrophic consequences if ignored. Organizations must adopt proactive strategies to detect, analyze, and resolve these issues before they escalate. By investing in advanced monitoring, predictive analytics, and automation, enterprises can safeguard their operations, reduce costs, and build long-term resilience. In a world where the smallest oversight can lead to the largest disruptions, vigilance and innovation are the keys to thriving in complexity.”
About HEAL Software
HEAL Software is a renowned provider of AIOps (Artificial Intelligence for IT Operations) solutions. HEAL Software’s unwavering dedication to leveraging AI and automation empowers IT teams to address IT challenges, enhance incident management, reduce downtime, and ensure seamless IT operations. Through the analysis of extensive data, our solutions provide real-time insights, predictive analytics, and automated remediation, thereby enabling proactive monitoring and solution recommendation. Other features include anomaly detection, capacity forecasting, root cause analysis, and event correlation. With the state-of-the-art AIOps solutions, HEAL Software consistently drives digital transformation and delivers significant value to businesses across diverse industries.